Myna
Система обработки документов для организаций и модуль управления телеграм ботом.

Публикация информации об этом проекте производится с разрешения правообладателя и руководства компании где я был исполнителем.
Итак задача:Есть некоторая организация которая хочет привести в порядок все свои документы, а главное улучшить и чаще всего “упростить” их создав более легкие версии, создать новый реестр документов и дать доступ к ним к телеграм боту который бы выдавал ссылки на документы и давал краткие выжимки из документов без необходимости открывать полные версии. Это должно быть удобное, защищенное и современное веб приложение с полным контролем учетных записей, историей, логами, инструментами для обработки, сортировки и преобразования документов, возможностью вести нормальный датаколлектор и управлять телеграм ботом.
Вызов принят. На всю разработку с первой строчки кода, до финального релиза (MVP был готов уже через месяц) ушло ровно два месяца.
Данная статья демонстрационная и данный проект не будет работать нигде кроме организации заказчика.
В первую очередь я придумал имя проекта, Myna — во первых это название птички Майна которых очень много в Алматы, они очень способны, умны и главное могут повторять звуки других животных и даже изменять их под свои нужды. Очень похоже на техническое задание проекта, да? Ну еще так как почти все мои проекты имеют двойные смыслы на казахском языке, думаю что Myna еще и подчеркивает ценность проекта.
Полетели разбирать все по полочкам!
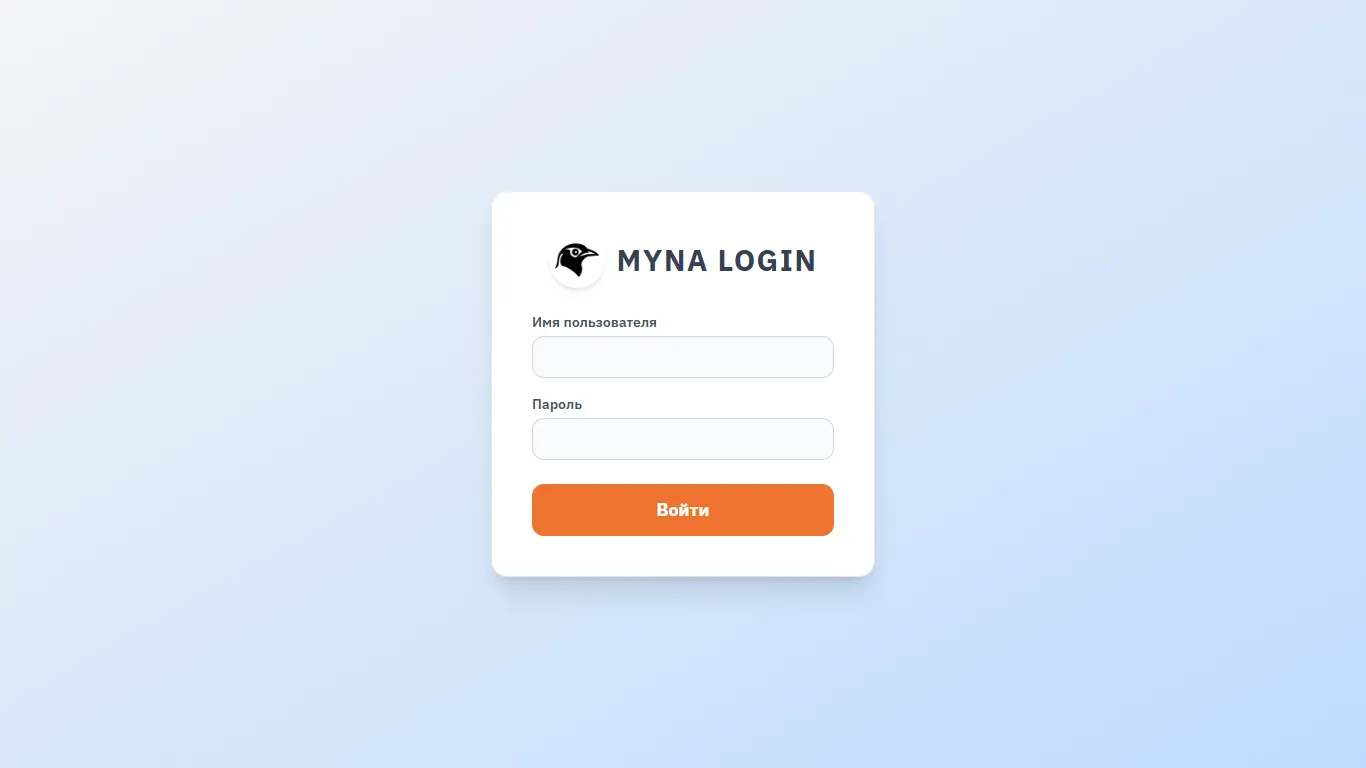
Первое что мы видим — это форма авторизации. Есть два типа пользователей (в целом можно придумать любые роли), отличие между пользователи это возможность или невозможность изменять настройки системы.
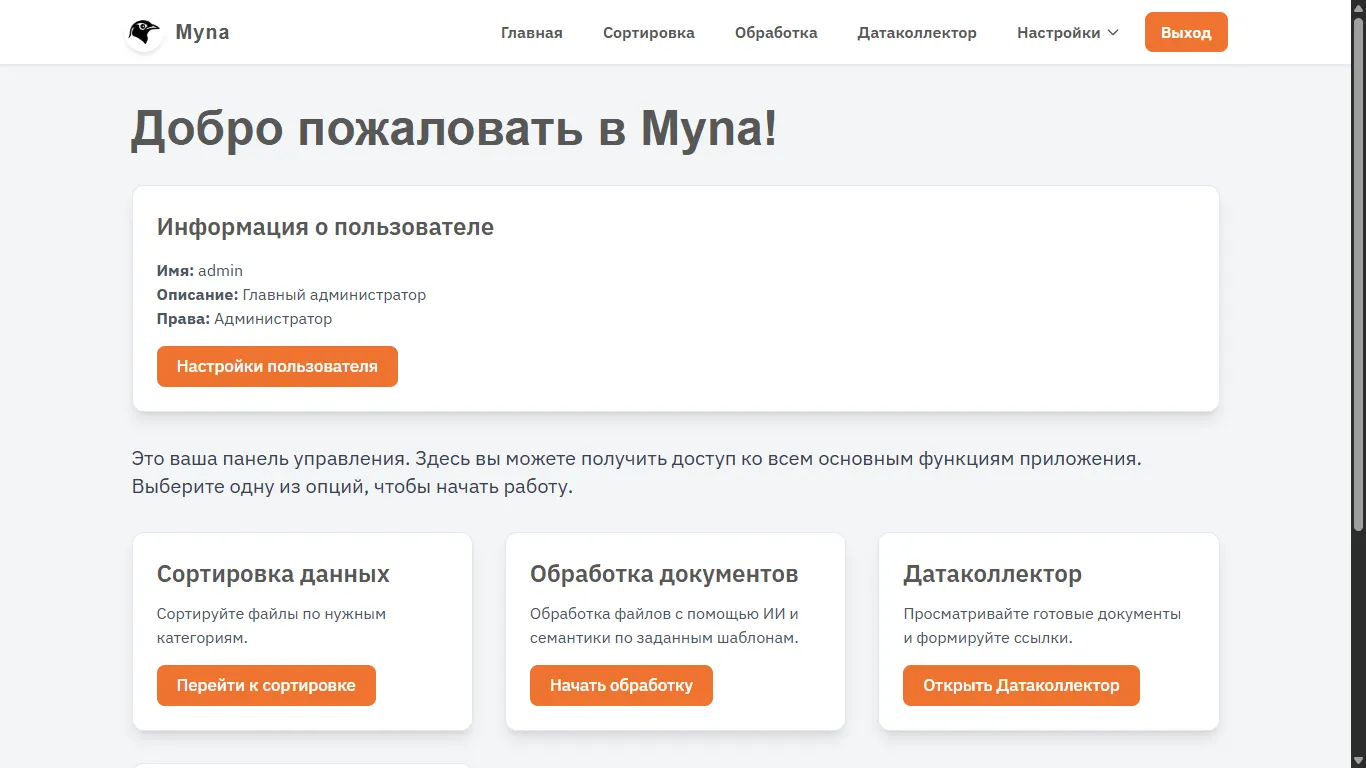
После авторизации попадаем на главный экран, тут нет особо ничего интересного, в будущем хочу отображать тут разную аналитику и пуши, но пока просто дублируем кнопки, показываем информацию о пользователе и кратко описываем каждый из разделов (в кадр не попала еще кнопка с настройками).
На данном этапе немного отвлекусь и кратко объясню порядок работы:
1. Сортировка исходных документов опираясь на существующий реестр
2. Перенос исходных документов с применением их существующих категорий и кодов
3. Обработка документов с помощью ИИ и перенос в итоговый датаколлектор
Чтобы в кадр попала вся страница, я немного уменьшил масштаб страницы. Во время сортировки нам по шагам объяснят что делать, пока никто не путался и не нарушал порядок.
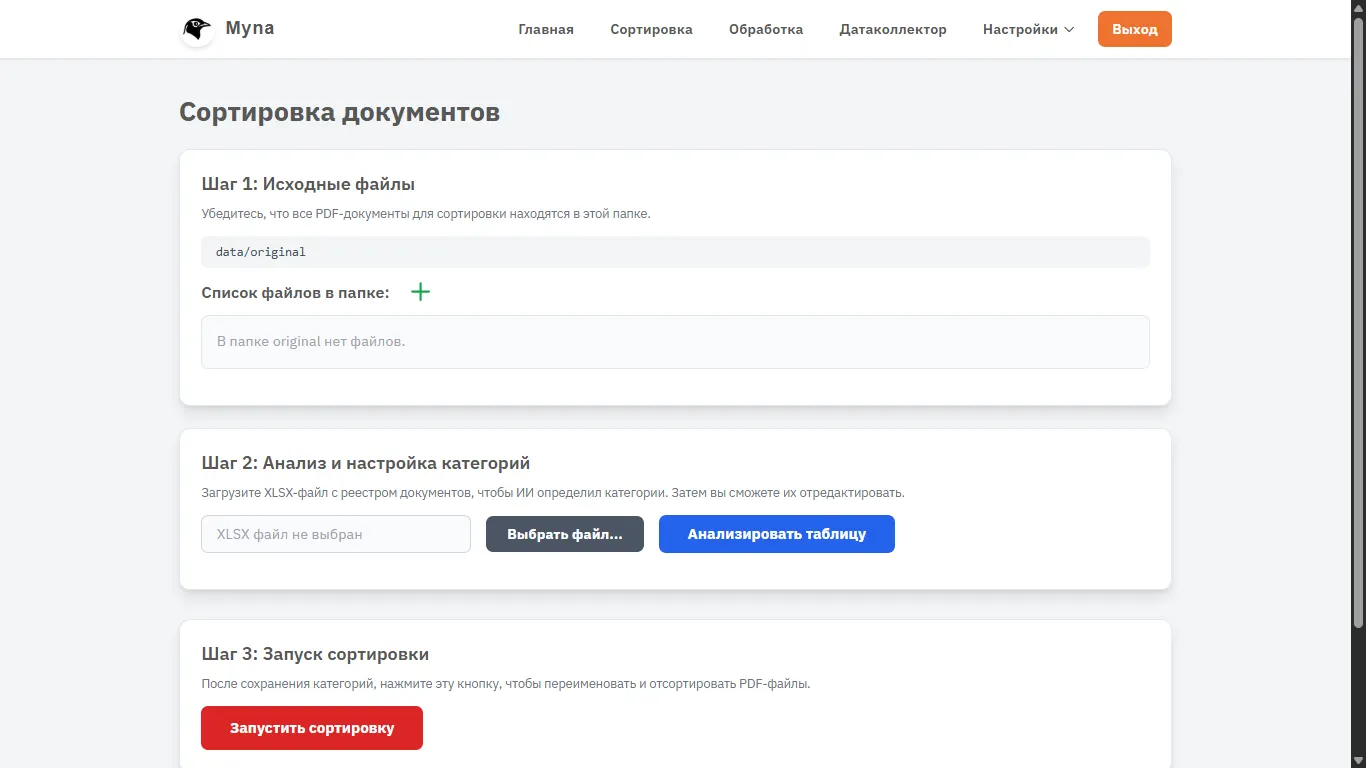
Исходные файлы. Добавлю сюда пока пару своих файлов. Аналитическую записку и ФЭО по одному из своих проектов.
Как видно система говорит что документы будут помещены в папку data/original
Это важно, потому что любую из папок для работы системы можно менять. По умолчанию есть три каталога — original для исходных файлов, sorted для файлов после сортировки, присвоения кодов и переименования, complete для файлов после финальной обработки. Но в настройках можно изменить их как угодно (надеюсь их не испугает Linux).
Для примера я создам новую таблицу которая сыграет роль существующего реестра документов с кодами, описанием, названиями файлов.

Получилась небольшая таблица, хоть тут и два пункта, думаю с этим можно работать.CBA — Cost-Benefit AnalysisPB — Policy Brief
Я сразу проанализировал таблицу и как видно, обе категории с названиями и описанием успешно определились. Важно подчеркнуть — настоящий реестр заполнялся годами, он гораздо тяжелее, содержит огромное количество кодов, наименований, структурирован и имеет разные подкатегории. Но он всегда успешно определяется с помощью ИИ.
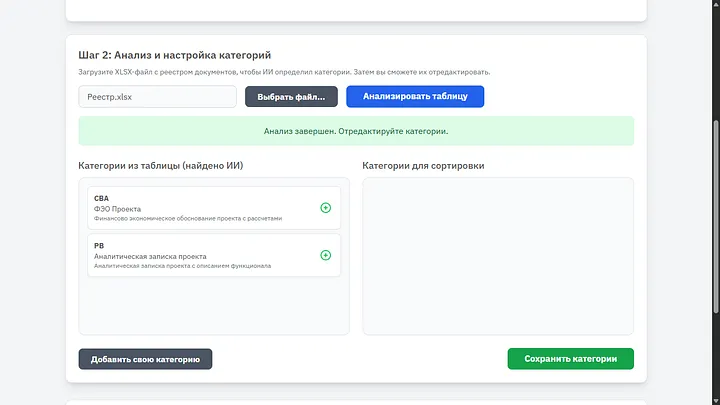
Важно перенести нужные категории вправо, при необходимости можно изменить их название или описание, можно добавить новую категорию если хотим, а затем сохранить. Система будет работать только с теми категориями которые пользователь выбрал.
Нажимаем “Запустить сортировку” в самом низу страницы и переходим во вкладку “Обработка”.
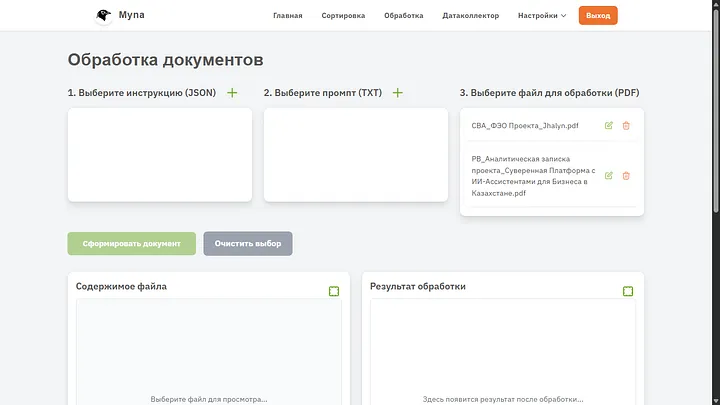
Итак, остановимся тут чуть подробнее. Что нужно чтобы документ был обработан с помощью ИИ правильно? Наверняка хороший промпт и желательно стиль на который он сможет опираться. Сейчас займемся созданием и стилей и промптов. Пока можно видеть что оба документа которые я загрузил получили правильные коды и более конструктивные названия.
Создание JSON — это по сути стиль для нашего документа, он содержит в себе CSS, можно написать его вручную если знать что писать, либо доверится опять же ИИ, я ввел такой параметр и получил очень хороший результат.
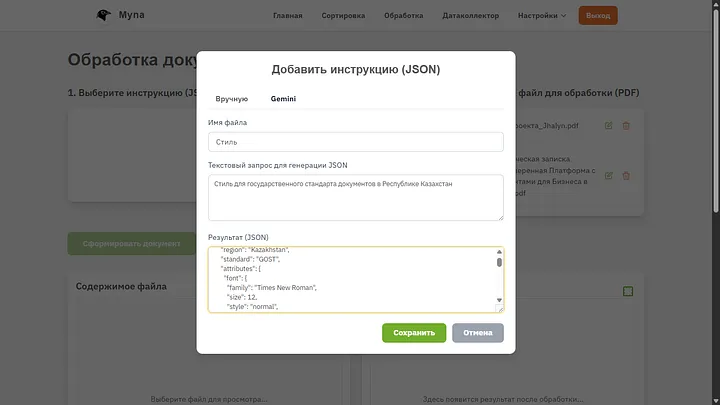
Если поместить в JSON просто CSS это тоже сработает, но во время генерации мы получили очень много дополнительной информации которая тоже понадобится ИИ. Если пользователь достаточно продвинут, он может написать код сам. В любом случае можно попросить ИИ сгенерировать что угодно, хоть разноцветные буквы с комиксным шрифтом.
Редактирование промпта. Тут важно задать как можно больше информации и инструкций, это самый важный шаг. Во время настоящей работы эти файлы могут быть очень большими и включать очень важные шаги во время обработки документа, я же для наглядности все очень упростил и просто сказал ему сделать версии короче, без воды и убрать ошибки.
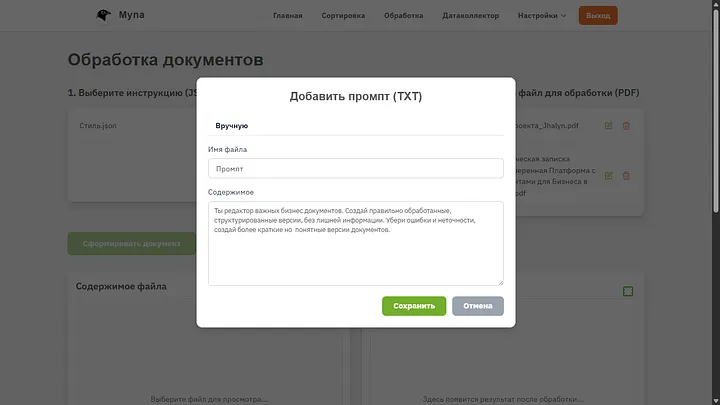
Когда мы щелкаем по любому документу из списка, в окне предпросмотра мы можем увидеть полный текст.
И для удобства есть еще и просмотр на весь экран в модальном окне с пагинацией страниц.
Нажимаем заветную кнопку “Сформировать документ”, видим текст “Идет генерация, пожалуйста подождите”.
Если документ маленький, как мои, то генерация пройдет быстро. Если там документ на 50+ страниц, придется подождать пару минут.
Генерация проходит в три этапа:1. Выделяем весь текст из PDF документа и делим его на сегменты2. Обрабатываем документ согласно текстовой инструкции и помещаем итог в буфер3. Применяем к тексту из буфера стиль который мы выбрали
Все этапы, это отдельные запросы к ИИ, лучше их не объединять иначе выходит множество артефактов, тесты показали что лучше немного усложнить и сделать несколько запросов.
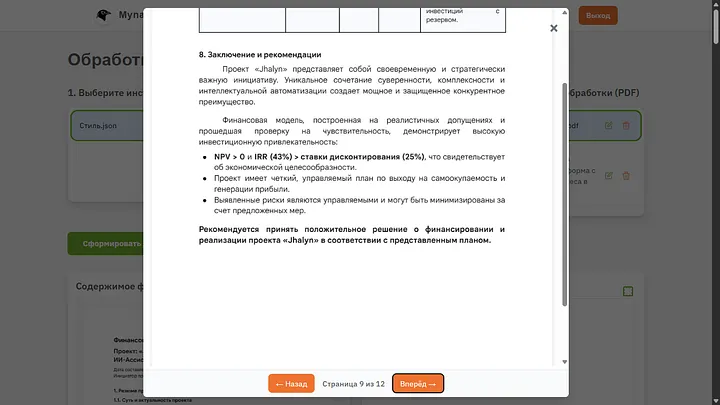
Через несколько секунд я получил вот такой итог:

Это пока HTML, теперь задача сохранить его в датаколлекторе, перемещаемся в самый низ и видим еще один приятный бонус.
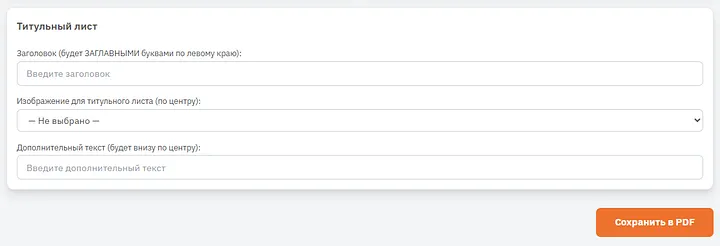
Мы можем задать документу титульный лист (если захотим), дать ему заголовок, выбрать изображение и текст для колонтитула. Пока пропустим это за ненадобностью и просто сохраним документ.
На всякий случай обработал и второй документ.Теперь важный момент. После каждого сохранения документа, информация о нем помещается в специальную таблицу. Это по сути новый реестр документов, он хранит код, наименование, путь где лежит документ и его summary — краткую выжимку о сути документа (это важно для работы в будущем).Саму таблицу можно будет увидеть в настройках, но об этом позже. Пока переходим в датаколлектор.
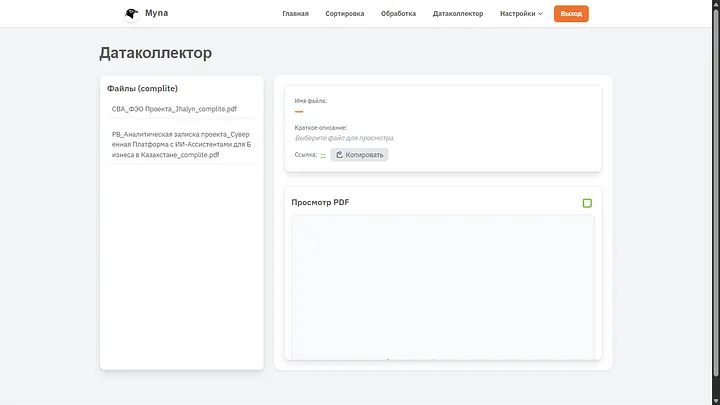
Просто, функционально, доступно. Как видно оба файла после генерации содержат правильные имена, коды и они могут попасть сюда только после обработки ИИ (либо добавления вручную, но об этом тоже чуть-чуть позже). Вообще, при генерации тут отображаются еще и два дебаг файла чтобы оперативно выявить плохо обработанный документ и как все это работало с точки зрения ИИ, но я их удалил для чистоты, потом покажу инструмент еще круче.
Я запускаю проект в отдельной версии на своем компьютере, понятное дело что для FLASK в моем случае не будет обратного прокси, поэтому мы увидим localhost с дефолтным портом и очень ужасную ссылку, простите меня за это.
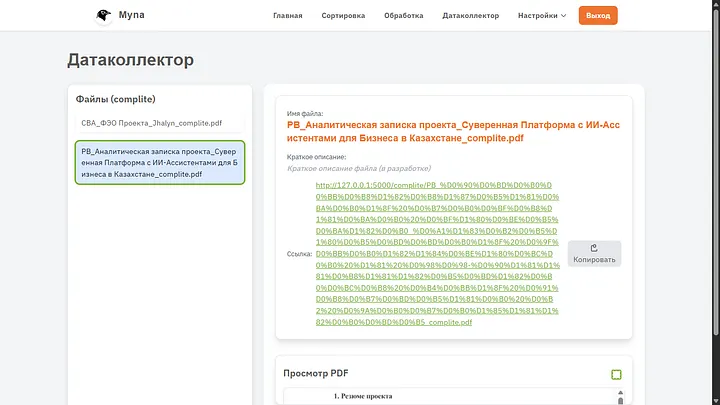
Если посмотреть что получилось, то видно что ИИ точно следовал инструкции, стиль действительно тот что я задал на генерации, и он следовал инструкции которую я написал. Из ошибок могу выявить что заголовок не стоит по центру, но этого нет ни в стиле ни в инструкции, так что простим бездушной машине такую оплошность.

Вот в целом и все. Сортировка — Обработка — Датаколлектор.
Называть это датаколлектором конечно громко сказано, но хочется ведь побольше важности в проект. Отсюда можно делится файлами напрямую, просто скопировав ссылку, либо просматривать имеющиеся. Хорошо? Хорошо же.
Пока перейдем в настройки, там три пункта — основные, история, бот. Расскажу обо всем подробно, это важно. Кое-что я очистил по понятным причинам, но итак понятно что и как должно работать, буду показывать отрывками потому что весь раздел никак не поместит на скриншот.
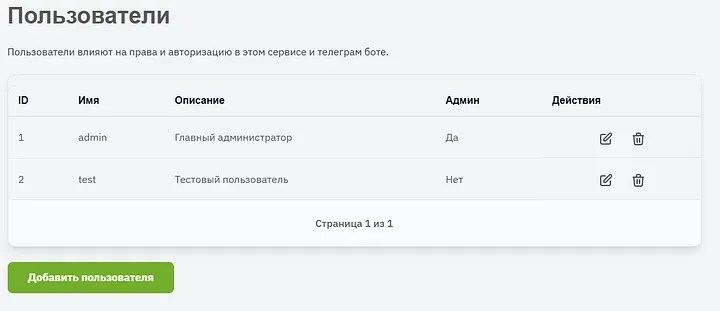
Добавляем пользователей, задаем им описание, выдаем права. Любого пользователя можно удалить или отредактировать (включая пароль для входа).
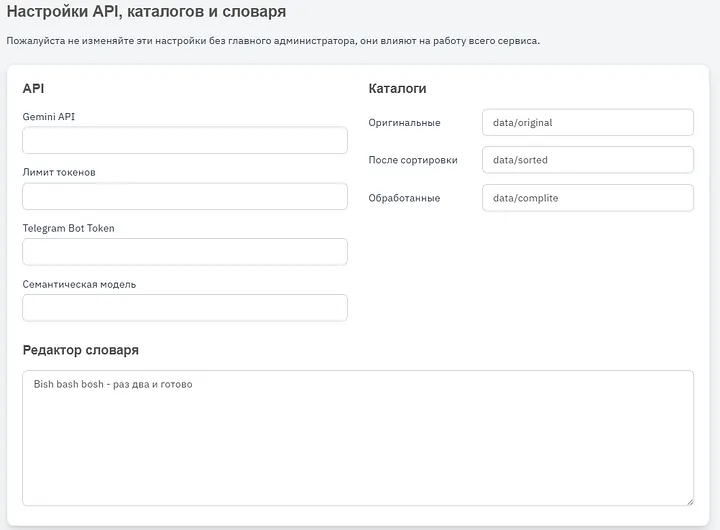
Gemini API — это ключ для облачного API GeminiЛимит токенов — на всякий случай, обычно я ставлю доступный лимит контекстного окнаTelegram Bot Token — нужен для работы бота, этот токен выдает только Bot FatherСемантическая модель — важна для работы с таблицами и summary. Как и в большинстве своих проектов я использую sentence transformerКаталоги — как и говорил, можем указать любые какие захотим, можно даже менять их по ходу работы и затем прыгать между разными версиями папок с разными документами.Редактор словаря — это нужно потому что во время обработки он используется, есть разная очень специфическая терминология и описание, это не буквально словарь с переводами, это словарь с описаниями (но иногда и с переводами).
Тут можно загрузить сколько угодно картинок для обложек с документами. Я для наглядности загрузил только свою лисичку Ару. Картинки можно смотреть в модальном окне на весь экран.
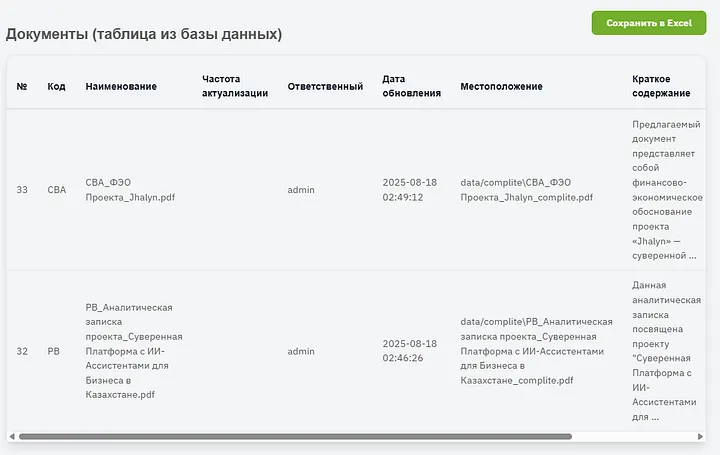
А вот и итоговая таблица о которой я говорил выше. Ее можно сохранить в виде XLSX файла, или смотреть прямо тут, справа есть еще столбцы где можно сразу открыть или скачать документ. Как видно summary определяется хорошо, есть ограничение на показ текста в ячейках, на самом деле его там намного больше.
Перейдем в следующий раздел настроек — История. Это и не настройки конечно, но я посчитал это самым разумным местом куда можно поместить эту страницу.
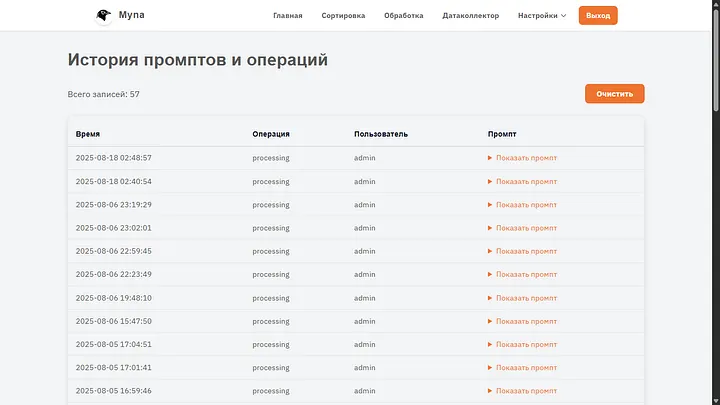
Тут хранятся вообще все действия пользователей с документами, кто их обрабатывал, как и что происходило в процессе.
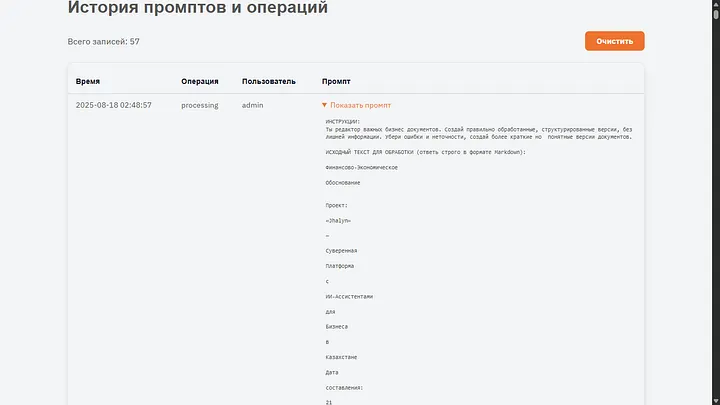
Весь текст документа, инструкция и словарь уходят в виде единого задания для ИИ. Туда же прилетает еще и JSON для вспомогательной информации, он в любом случае повторно обрабатывается во время генерации HTML.
Третий раздел называется “Бот”, тут в целом как в датаколлекторе показывается список документов с которыми работает бот, но важное отличие — возможность добавлять сюда документы напрямую.
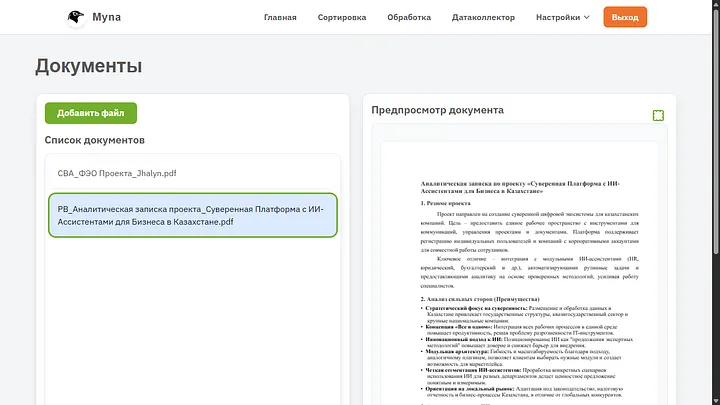
Тоже окно для предпросмотра. Если мы хотим добавить файл без сортировки и без обработки, это можно сделать одной кнопкой. Но ИИ в любом случае его считает чтобы добавить в таблицу реестр и создаст для него summary.
Осталось показать работу бота. У меня есть проект Promptly, по сути код бота в этом проекте это как раз он, только сильно модифицированный и намного упрощенный. Тестовый токен остался тоже от него.
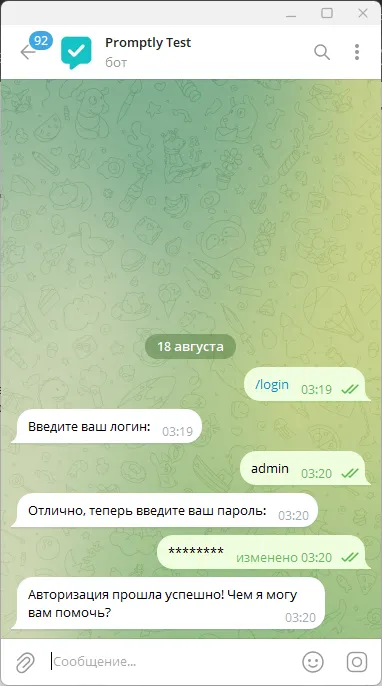
Авторизация ровно теми же учетными данными что и задаются в основном проекте. Можноиспользовать одни учетные записи несколькими пользователями, ничего страшного нет. Но сессия в боте держится только 8 часов, затем нужно будет авторизоваться снова. Информация записывается в отдельную для бота таблицу и привязывается к userID телеграм аккаунта, более никакой информации о пользователе мы не храним.
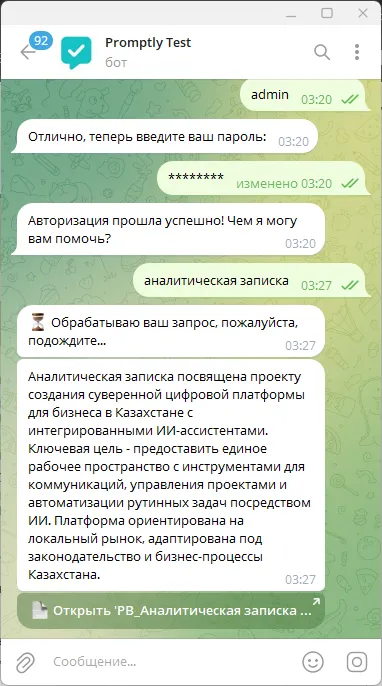
А вот собственно и результат запроса. Для каждого документа отображается краткое описание по запросу, а затем инлайн кнопка со ссылкой на сам документ.
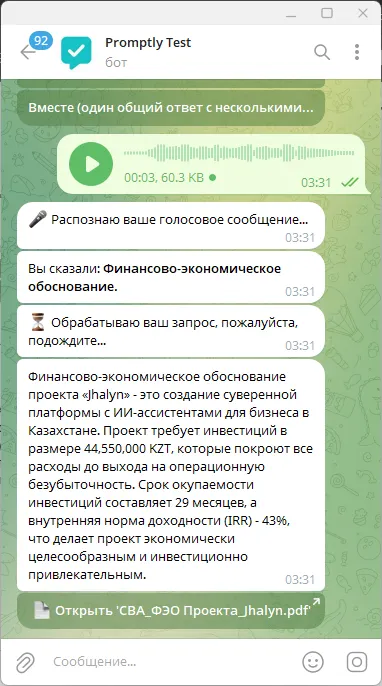
Если релевантных документов по запросу несколько, то и сообщений будет несколько (но не больше трех) с кратким описанием каждого и ссылками на документы. Есть внутренняя настройка прямо в боте, можно выбрать как показывать результаты — одним сообщением или отдельными. В случае если мы хотим одно сообщение то ответ будет сгенерирован таким образом чтобы пользователь обратил внимание на различия или важные моменты в документах, а затем получил список документов кнопками в столбик.
Ну и конечно же бонус — можно отправлять запросы даже голосом, причем на трех языках (английский, казахский, русский).
Вот такой получился интересный и функциональный проект.
Если вы дочитали до конца, спасибо. Надеюсь никто не устал, а если да, то вот еще информация о техническом стеке проекта:
Весь проект был написан на Python 3, а за основу веб-приложения был взят микро-фреймворк Flask. Для работы с базой данных используется SQLite, при этом для асинхронных операций задействован aiosqlite, а для более простых — стандартный sqlite3. Работа с файлами реализована с помощью стандартных модулей Python (os, pathlib, shutil) и Werkzeug, который обеспечивает безопасную загрузку файлов. Для обработки документов был создан собственный модуль fileprocess, который, в свою очередь, использует extract_text_from_pdf для извлечения текста из PDF-файлов. Считывание Excel-файлов осуществляется через собственный модуль read_xlsx_to_list, а для генерации PDF из HTML-содержимого используется Weasyprint. Для работы с внешним API ИИ используется собственный модуль-обёртка gemini, разработанный для взаимодействия с Google Gemini API. Проект также включает в себя систему логирования, парсер Markdown и стандартные модули для работы с JSON и регулярными выражениями. Что касается фронтенда, он построен на шаблонах Jinja2 и использует статические файлы CSS и JS. Также предусмотрена работа с пользовательскими настройками, ролями и загрузкой изображений, а миграции и инициализация базы данных происходят “на лету”.
Если честно я просто попросил ИИ написать этот абзац прямо внутри VScode :)
Спасибо за внимание всем прочитавшим!