Myna
Ұйымдарға арналған құжаттарды өңдеу жүйесі және Telegram ботын басқару модулі.

Бұл жоба туралы ақпарат құқық иеленушінің және мен орындаушы болған компания басшылығының рұқсатымен жариялануда.
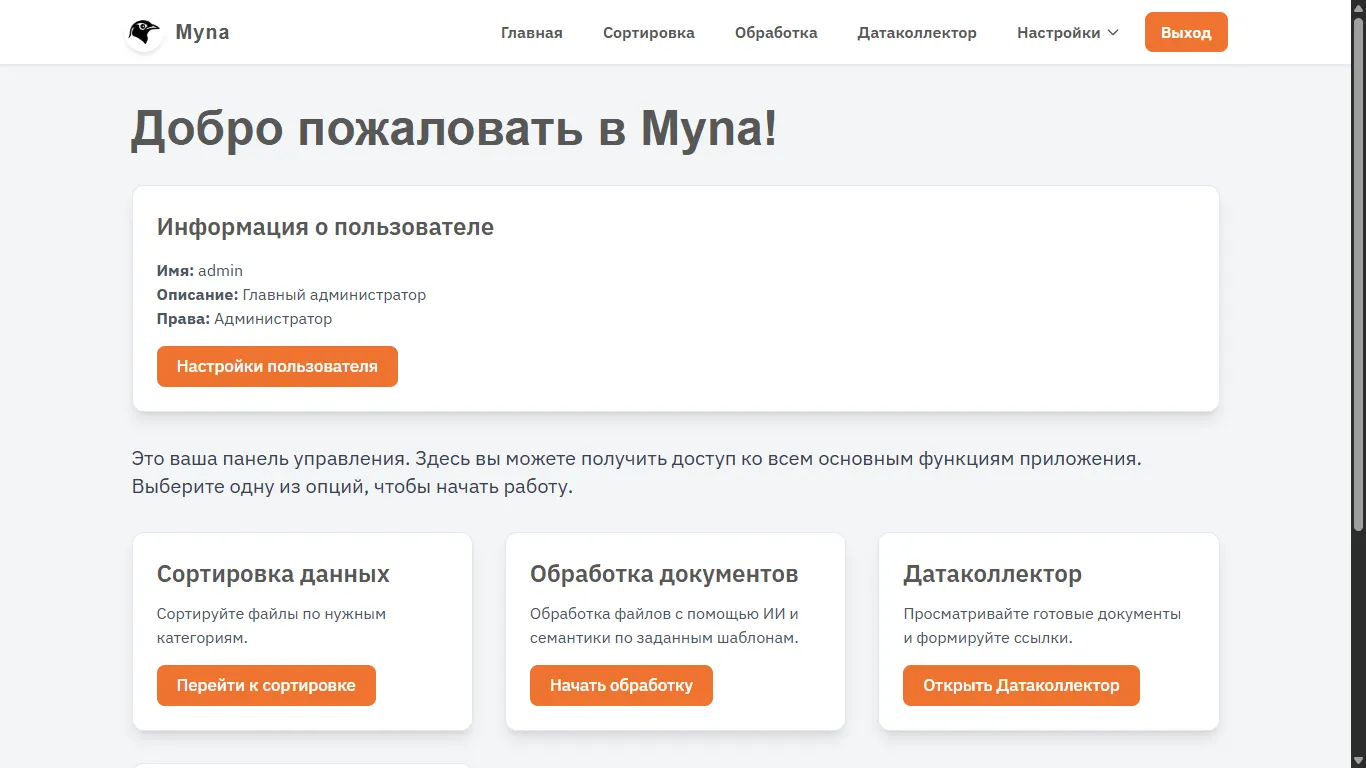
Сонымен, тапсырма: Барлық құжаттарын ретке келтіргісі келетін, ең бастысы олардың жеңілдетілген нұсқаларын жасау арқылы оларды жетілдіріп, жиі «оңайлатқысы» келетін, жаңа құжаттар тізілімін жасап, оларға құжаттардың толық нұсқасын ашпай-ақ сілтемелер мен қысқаша мазмұнын беретін Telegram ботқа қолжетімділік бергісі келетін белгілі бір ұйым бар. Бұл пайдаланушы есептік жазбаларын толық бақылайтын, тарихы, логтары, құжаттарды өңдеу, сұрыптау және түрлендіру құралдары бар, дұрыс деректер жинаушыны жүргізуге және Telegram ботты басқаруға мүмкіндік беретін ыңғайлы, қорғалған және заманауи веб-қосымша болуы керек.
Қабылданды. Кодтың бірінші жолынан бастап соңғы релизге дейінгі барлық әзірлеуге (MVP бір айдан кейін дайын болды) тұп-тура екі ай кетті.
Бұл мақала демонстрациялық сипатта және бұл жоба тапсырыс беруші ұйымнан басқа еш жерде жұмыс істемейді.
Біріншіден, мен жобаның атын ойлап таптым, Myna — біріншіден, бұл Алматыда өте көп кездесетін Майна құсының аты, олар өте қабілетті, ақылды және ең бастысы басқа жануарлардың дыбыстарын қайталап, тіпті оларды өз қажеттіліктеріне қарай өзгерте алады. Жобаның техникалық тапсырмасына өте ұқсас, солай емес пе? Сонымен қатар, менің барлық дерлік жобаларымның қазақ тілінде екі мағынасы болғандықтан, Myna да жобаның құндылығын баса көрсетеді деп ойлаймын (қазақша «Мына» деген мағынада).
Қане, бәрін егжей-тегжейлі талдайық!
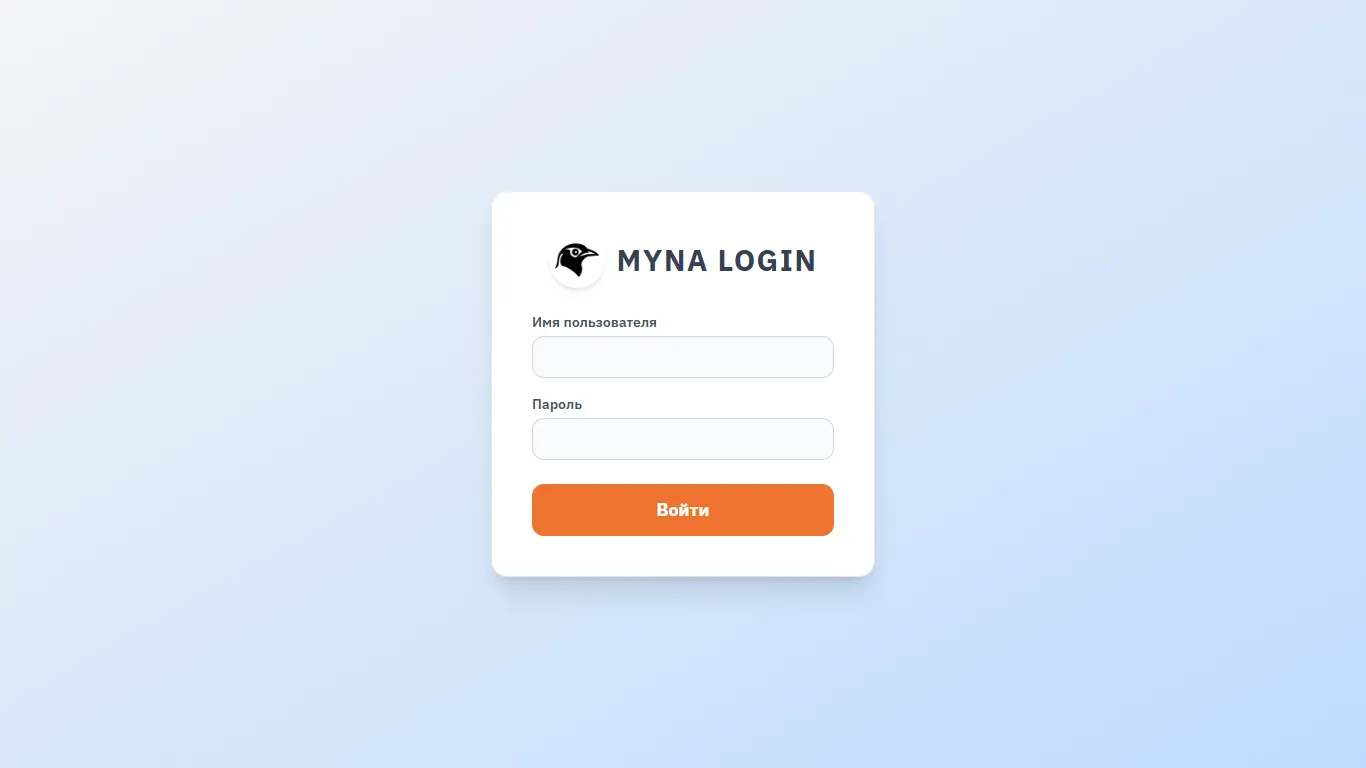
Біздің бірінші көретініміз — бұл авторизация формасы. Пайдаланушылардың екі түрі бар (жалпы кез келген рөлдерді ойлап табуға болады), пайдаланушылар арасындағы айырмашылық — жүйе параметрлерін өзгерту мүмкіндігінің бар немесе жоқ болуы.
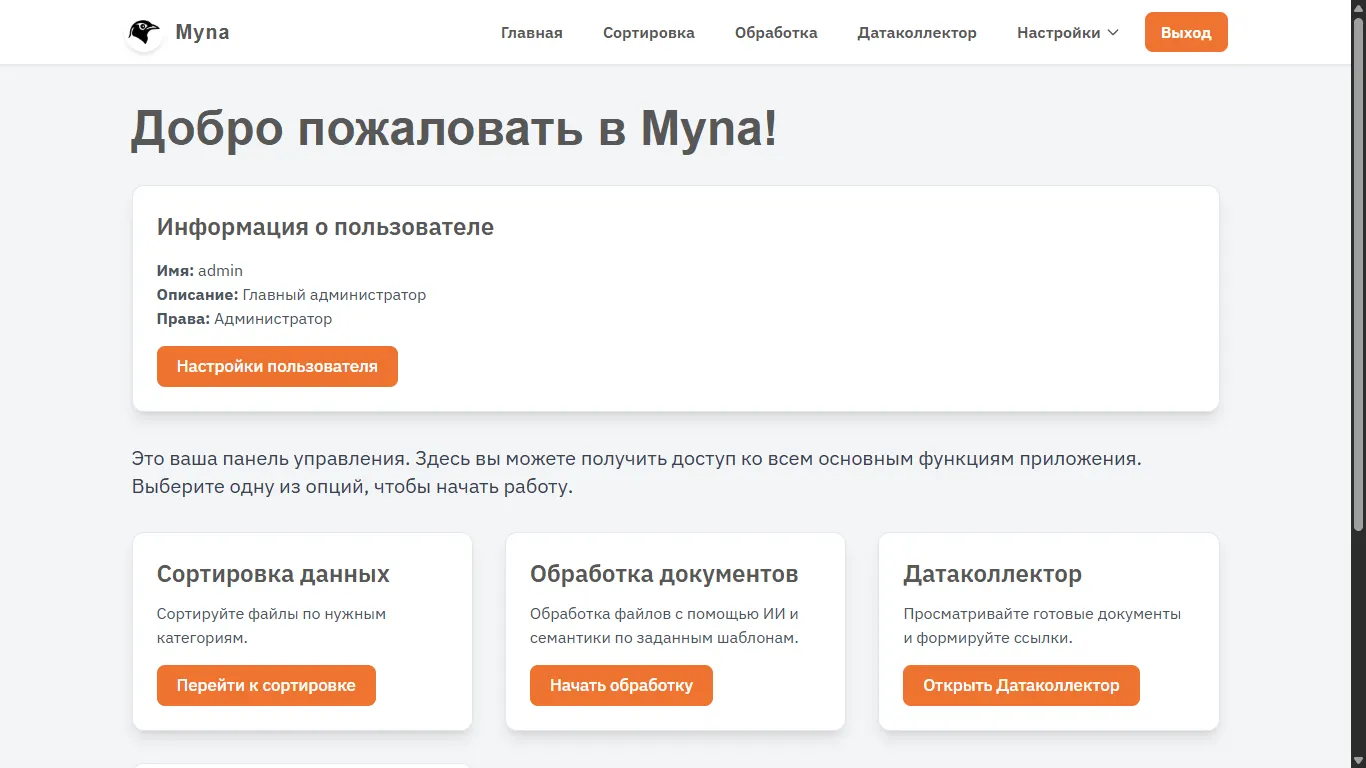
Авторизациядан кейін біз басты экранға өтеміз, мұнда әзірге қызықты ештеңе жоқ, болашақта мұнда әртүрлі аналитика мен пуш-хабарламаларды көрсеткім келеді, бірақ әзірге түймелерді қайталаймыз, пайдаланушы туралы ақпаратты көрсетеміз және әр бөлімді қысқаша сипаттаймыз (кадрға параметрлері бар түйме сыймай қалды).
Бұл кезеңде сәл шегініс жасап, жұмыс тәртібін қысқаша түсіндіремін:
1. Қолданыстағы тізілімге сүйене отырып, бастапқы құжаттарды сұрыптау
2. Бастапқы құжаттарды олардың қолданыстағы санаттары мен кодтарын қолдана отырып тасымалдау
3. Құжаттарды ИИ көмегімен өңдеу және қорытынды деректер жинаушыға тасымалдау
Бүкіл бет кадрға сыюы үшін мен беттің масштабын сәл кішірейттім. Сұрыптау кезінде бізге не істеу керектігі қадам бойынша түсіндіріледі, әзірге ешкім шатасып, тәртіпті бұзған жоқ.
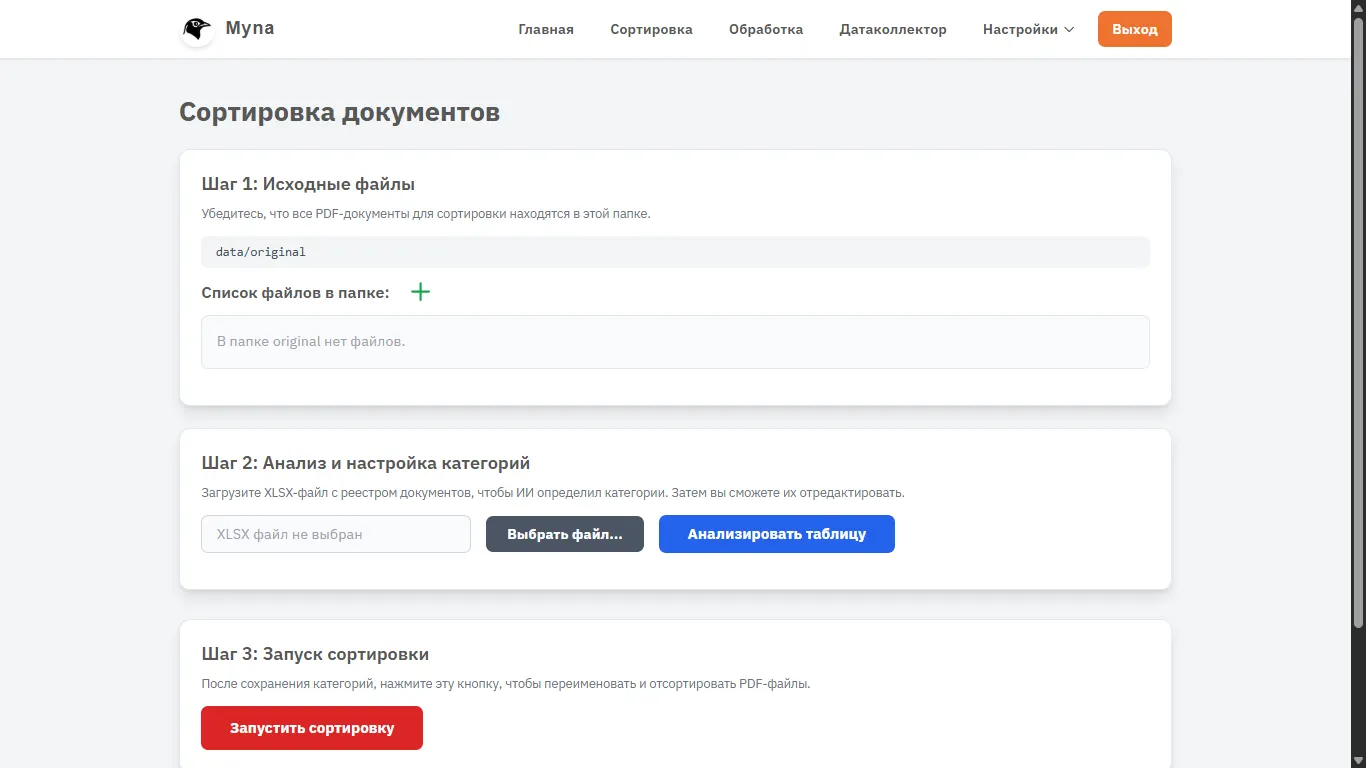
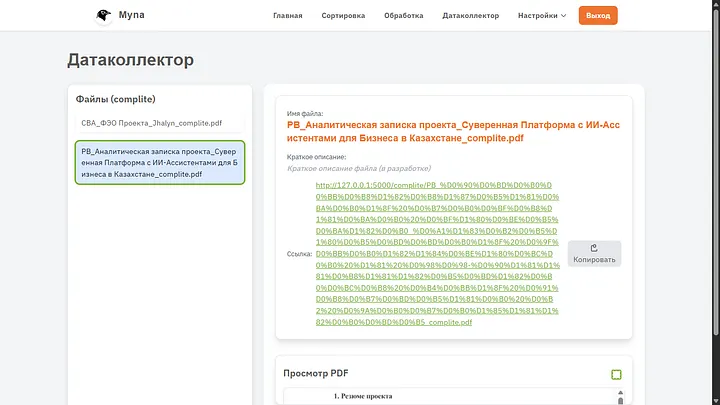
Бастапқы файлдар. Әзірге осында өзімнің бір-екі файлымды қосамын. Өз жобаларымның бірі бойынша аналитикалық жазба және ФЭО.
Көріп тұрғаныңыздай, жүйе құжаттар data/original қалтасына орналастырылатынын айтуда.
Бұл маңызды, өйткені жүйе жұмысы үшін кез келген қалтаны өзгертуге болады. Әдепкі бойынша үш каталог бар — original бастапқы файлдар үшін, sorted сұрыптаудан, кодтарды тағайындаудан және атауын өзгертуден кейінгі файлдар үшін, complete қорытынды өңдеуден кейінгі файлдар үшін. Бірақ параметрлерде оларды қалауыңызша өзгертуге болады (оларды Linux қорқытпайды деп үміттенемін).
Мысалы, мен кодтары, сипаттамасы, файл атаулары бар қолданыстағы құжаттар тізілімінің рөлін атқаратын жаңа кесте жасаймын.

Шағын кесте шықты, мұнда екі тармақ болса да, бұнымен жұмыс істеуге болады деп ойлаймын. CBA — Cost-Benefit Analysis PB — Policy Brief
Мен кестені бірден талдадым және көріп тұрғаныңыздай, атаулары мен сипаттамасы бар екі санат та сәтті анықталды. Атап өту маңызды — нағыз тізілім жылдар бойы толтырылған, ол әлдеқайда ауыр, көптеген кодтарды, атауларды қамтиды, құрылымдалған және әртүрлі ішкі санаттары бар. Бірақ ол әрқашан ИИ көмегімен сәтті анықталады.
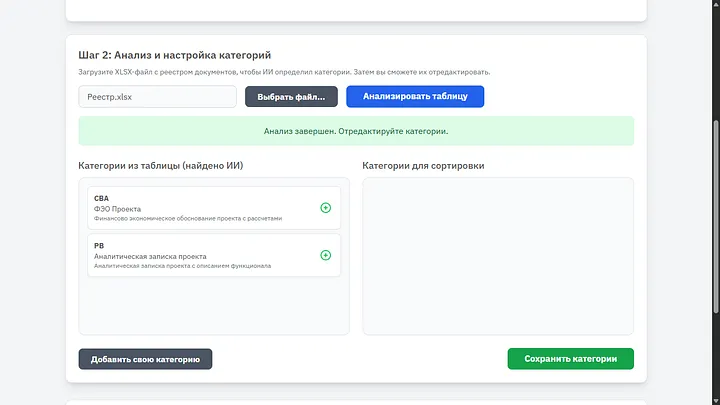
Қажетті санаттарды оңға жылжыту маңызды, қажет болса олардың атауын немесе сипаттамасын өзгертуге болады, қаласақ жаңа санат қосып, содан кейін сақтай аламыз. Жүйе тек пайдаланушы таңдаған санаттармен ғана жұмыс істейтін болады.
Беттің ең төменгі жағындағы «Сұрыптауды іске қосу» батырмасын басып, «Өңдеу» қойындысына өтеміз.
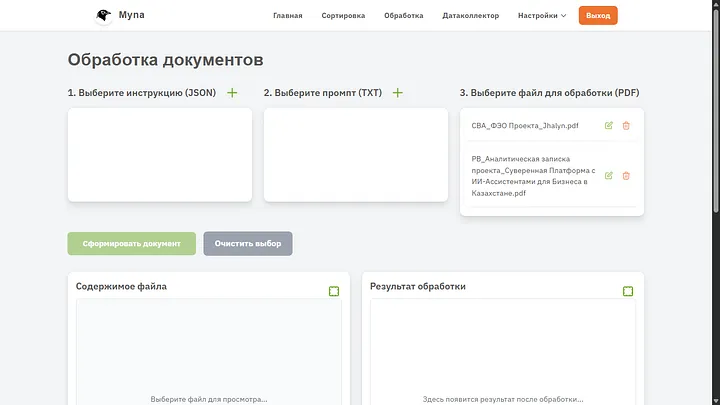
Сонымен, осы жерге толығырақ тоқталайық. Құжат ИИ көмегімен дұрыс өңделуі үшін не қажет? Әрине, жақсы промпт және ол сүйене алатын стиль болғаны дұрыс. Қазір стильдер мен промпттарды жасаумен айналысамыз. Әзірге мен жүктеген екі құжат та дұрыс кодтар мен анағұрлым конструктивті атаулар алғанын көруге болады.
JSON құру — бұл іс жүзінде біздің құжатымыздың стилі, ол өзінде CSS қамтиды, егер не жазу керектігін білсеңіз, оны қолмен жазуға болады, немесе тағы да ИИ-ге сенуге болады, мен осындай параметрді енгізіп, өте жақсы нәтиже алдым.
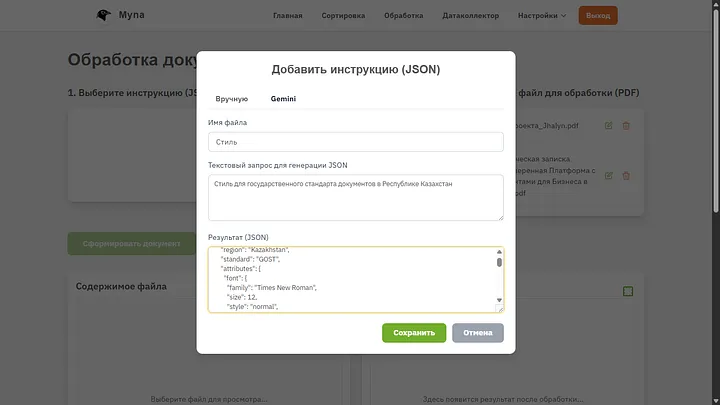
Егер JSON-ға жай ғана CSS орналастырсақ, бұл да жұмыс істейді, бірақ генерация кезінде біз ИИ-ге қажет болатын көптеген қосымша ақпарат алдық. Егер пайдаланушы жеткілікті деңгейде білікті болса, ол кодты өзі жаза алады. Қалай болғанда да, ИИ-ден кез келген нәрсені, тіпті комикстік қаріппен түрлі-түсті әріптерді генерациялауды сұрауға болады.
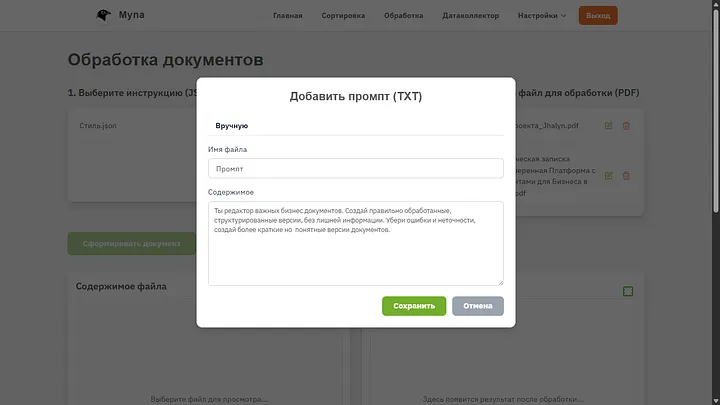
Промптты өңдеу. Мұнда мүмкіндігінше көбірек ақпарат пен нұсқаулар беру маңызды, бұл ең маңызды қадам. Нақты жұмыс кезінде бұл файлдар өте үлкен болуы мүмкін және құжатты өңдеу кезінде өте маңызды қадамдарды қамтуы мүмкін, мен көрнекілік үшін бәрін өте жеңілдеттім және оған жай ғана нұсқаларды қысқарақ, сусыз етуді және қателерді жоюды айттым.
Тізімдегі кез келген құжатты басқан кезде, алдын ала қарау терезесінде толық мәтінді көре аламыз.
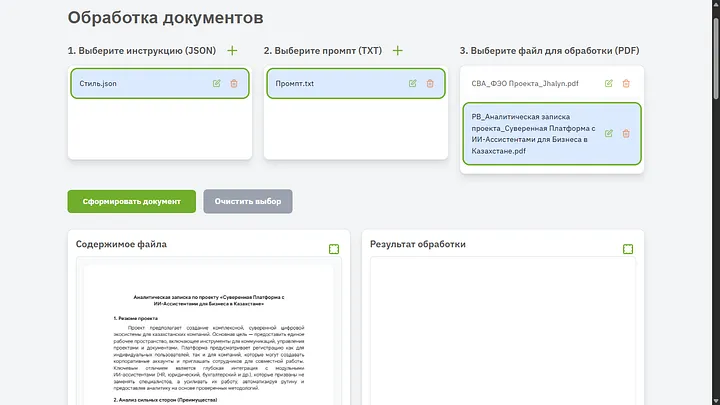
Және ыңғайлы болу үшін беттерді парақтау мүмкіндігі бар толық экранды модальды терезеде қарау мүмкіндігі де бар.
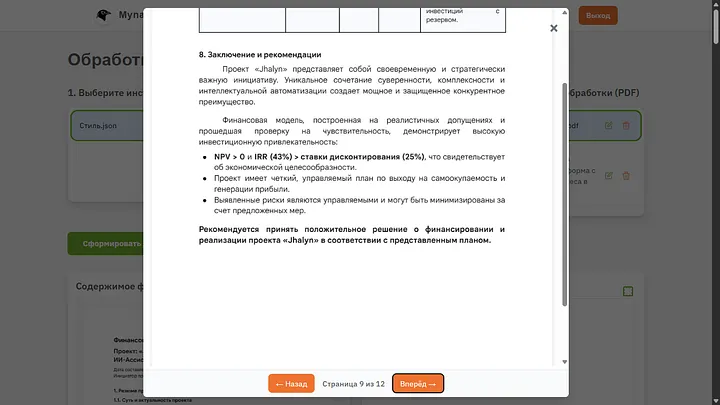
Көптен күткен «Құжатты қалыптастыру» батырмасын басамыз, «Генерация жүріп жатыр, күте тұрыңыз» деген мәтінді көреміз.
Егер құжат менікі сияқты шағын болса, генерация тез өтеді. Егер ол 50+ беттік құжат болса, бірнеше минут күтуге тура келеді.
Генерация үш кезеңде өтеді: 1. PDF құжаттан барлық мәтінді бөліп алып, оны сегменттерге бөлеміз 2. Құжатты мәтіндік нұсқаулыққа сәйкес өңдейміз және нәтижені буферге орналастырамыз 3. Буфердегі мәтінге біз таңдаған стильді қолданамыз
Барлық кезеңдер — ИИ-ге жеке сұраулар, оларды біріктірмеген дұрыс, әйтпесе көптеген артефактілер шығады, тесттер көрсеткендей, сәл күрделендіріп, бірнеше сұрау жасаған дұрыс.
Бірнеше секундтан кейін мен мынадай нәтиже алдым:

Бұл әзірге HTML, ендігі міндет оны деректер жинаушыда сақтау, ең төменге түсіп, тағы бір жағымды бонусты көреміз.
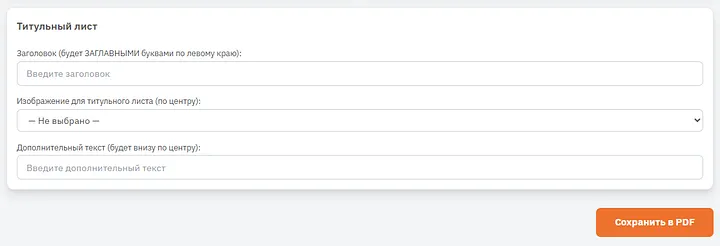
Біз құжатқа титулдық парақ бере аламыз (қаласақ), оған тақырып қойып, колонтитул үшін сурет пен мәтін таңдай аламыз. Әзірге бұны қажет емес деп өткізіп жібереміз де, құжатты жай ғана сақтаймыз.
Сақтық үшін екінші құжатты да өңдедім. Енді маңызды сәт. Құжатты әр сақтаған сайын, ол туралы ақпарат арнайы кестеге орналастырылады. Бұл іс жүзінде құжаттардың жаңа тізілімі, ол кодты, атауды, құжат орналасқан жолды және оның summary — құжаттың мәні туралы қысқаша үзіндіні сақтайды (бұл болашақ жұмыс үшін маңызды). Кестенің өзін параметрлерден көруге болады, бірақ бұл туралы кейінірек. Әзірге деректер жинаушыға өтеміз.
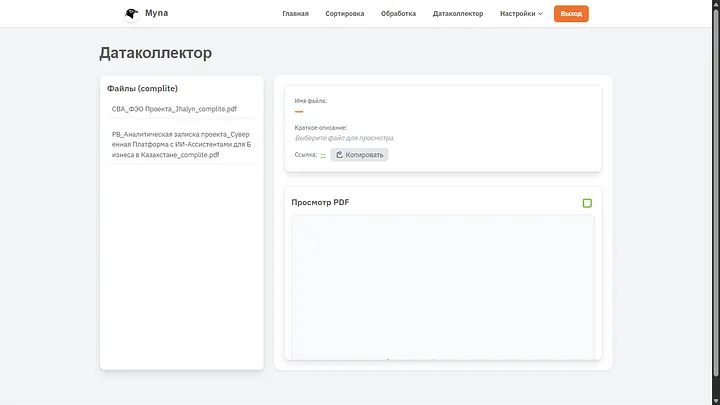
Қарапайым, функционалды, қолжетімді. Көріп тұрғаныңыздай, генерациядан кейін екі файл да дұрыс атаулар мен кодтарды қамтиды және олар мұнда тек ИИ өңдеуінен кейін ғана түсе алады (немесе қолмен қосу арқылы, бірақ бұл туралы да сәл кейінірек). Жалпы, генерация кезінде мұнда нашар өңделген құжатты және ИИ тұрғысынан мұның қалай жұмыс істегенін жедел анықтау үшін екі дебаг файлы көрсетіледі, бірақ мен тазалық үшін оларды өшіріп тастадым, кейін бұдан да керемет құралды көрсетемін.
Мен жобаны өз компьютерімде жеке нұсқада іске қосып отырмын, әрине, менің жағдайымда FLASK үшін кері прокси болмайды, сондықтан біз дефолттық портпен localhost-ты және өте сұмдық сілтемені көреміз, ол үшін кешірім сұраймын.
Нәтижесіне қарасақ, ИИ нұсқаулықты дәл орындағанын, стиль шынымен мен генерацияға қойған стиль екенін және ол мен жазған нұсқаулықты орындағанын көруге болады. Қателерден тақырыптың ортада тұрмағанын анықтай аламын, бірақ бұл стильде де, нұсқаулықта да жоқ, сондықтан жансыз машинаға мұндай олқылықты кешіреміз.

Жалпы барлығы осы. Сұрыптау — Өңдеу — Деректер жинаушы.
Мұны деректер жинаушы деп атау әрине тым артық айтылған, бірақ жобаға көбірек маңыздылық қосқымыз келеді ғой. Бұл жерден жай ғана сілтемені көшіріп алу арқылы файлдармен тікелей бөлісуге немесе бар файлдарды қарауға болады. Жақсы ма? Жақсы ғой.
Әзірге параметрлерге көшейік, онда үш тармақ бар — негізгі, тарих, бот. Барлығы туралы егжей-тегжейлі айтып беремін, бұл маңызды. Кейбір жерлерін түсінікті себептермен тазалап тастадым, бірақ ненің қалай жұмыс істеуі керектігі онсыз да түсінікті, скриншотқа бүкіл бөлім сыймайтындықтан, үзінділермен көрсетемін.
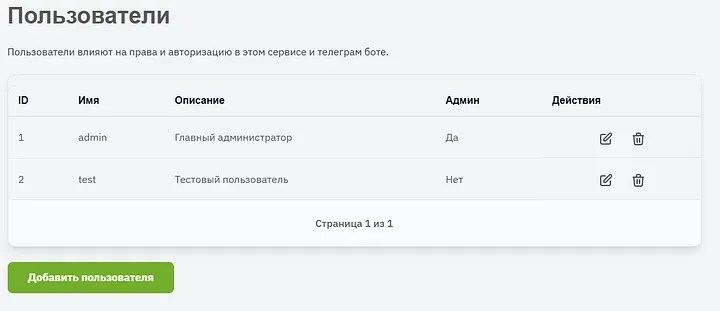
Пайдаланушыларды қосамыз, оларға сипаттама береміз, құқықтар береміз. Кез келген пайдаланушыны өшіруге немесе өңдеуге болады (кіру құпия сөзін қоса алғанда).
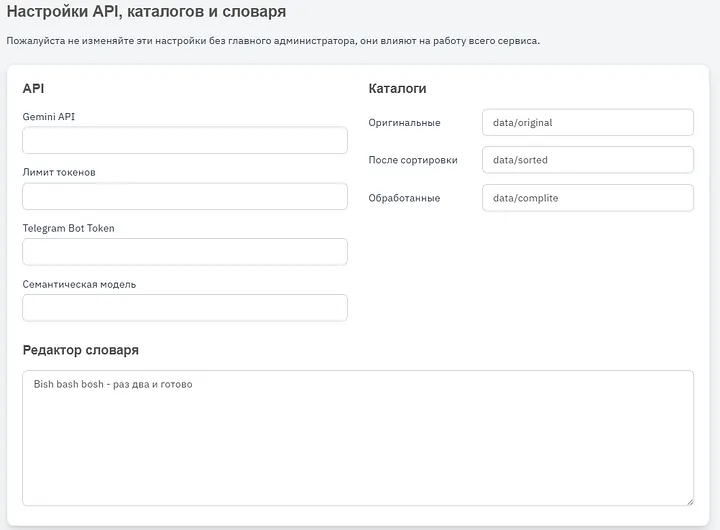
Gemini API — бұл бұлтты Gemini API кілті Токендер лимиті — сақтық үшін, әдетте мен қолжетімді контекстік терезе лимитін қоямын Telegram Bot Token — боттың жұмысы үшін қажет, бұл токенді тек Bot Father береді Семантикалық модель — кестелермен және summary-мен жұмыс істеу үшін маңызды. Өз жобаларымның көпшілігіндегідей, мен sentence transformer қолданамын Каталогтар — айтқанымдай, кез келгенін көрсете аламыз, тіпті жұмыс барысында оларды өзгертіп, содан кейін әртүрлі құжаттары бар қалталардың әртүрлі нұсқалары арасында ауыса аламыз. Сөздік редактор — бұл өңдеу кезінде қолданылатындықтан қажет, әртүрлі өте ерекше терминология мен сипаттамалар бар, бұл тікелей аудармалары бар сөздік емес, бұл сипаттамалары бар (бірақ кейде аудармалары да бар) сөздік.
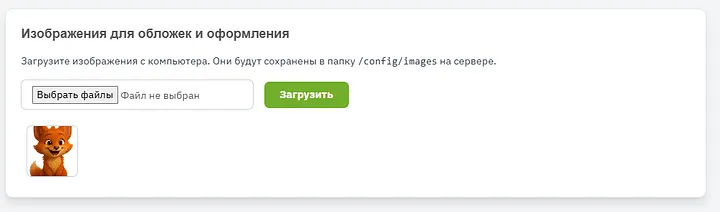
Мұнда құжаттары бар мұқабалар үшін қанша сурет болса да жүктей аласыз. Мен көрнекілік үшін тек өзімнің Ару түлкімді жүктедім. Суреттерді толық экранды модальды терезеде қарауға болады.
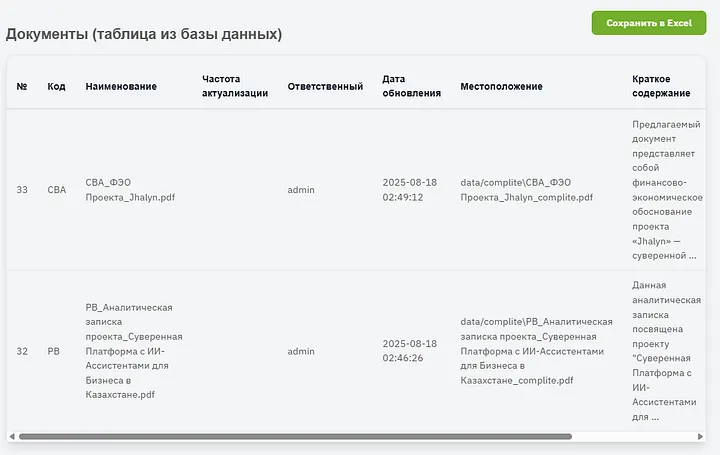
Міне, мен жоғарыда айтқан қорытынды кесте. Оны XLSX файлы түрінде сақтауға немесе дәл осы жерде қарауға болады, оң жақта құжатты бірден ашуға немесе жүктеп алуға болатын бағандар бар. Көріп тұрғаныңыздай, summary жақсы анықталады, ұяшықтарда мәтінді көрсету шектеуі бар, іс жүзінде ол жерде мәтін әлдеқайда көп.
Келесі параметрлер бөліміне өтейік — Тарих. Бұл әрине параметрлер емес, бірақ мен бұл бетті орналастыруға ең қолайлы жер осы деп санадым.
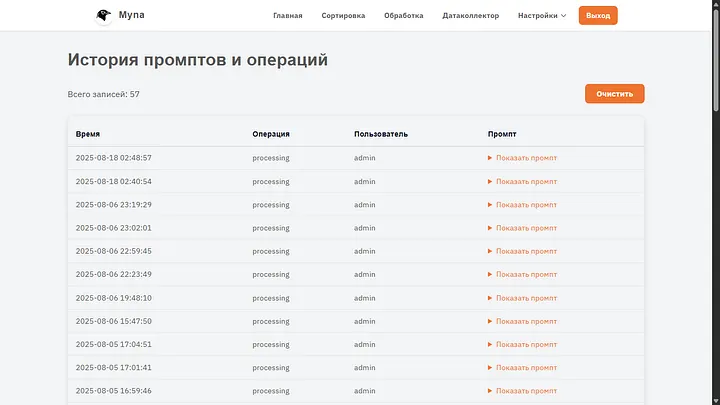
Мұнда жалпы пайдаланушылардың құжаттармен жасаған барлық әрекеттері, оларды кім өңдегені, процесс барысында не және қалай болғаны сақталады.
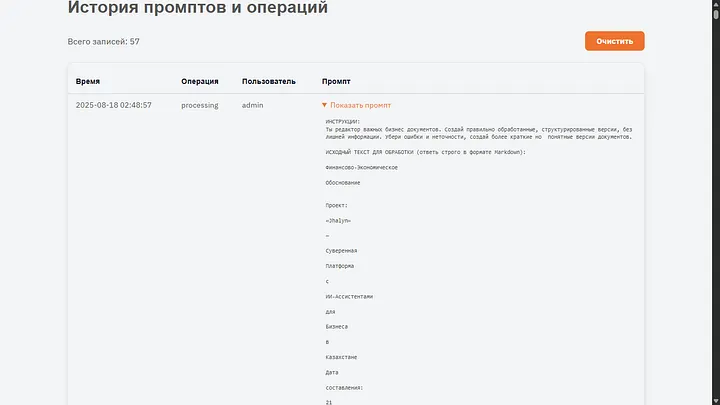
Құжаттың толық мәтіні, нұсқаулық және сөздік ИИ үшін бірыңғай тапсырма түрінде кетеді. Ол жаққа қосалқы ақпарат үшін JSON да келеді, ол қалай болғанда да HTML генерациялау кезінде қайтадан өңделеді.
Үшінші бөлім “Бот” деп аталады, мұнда жалпы деректер жинаушыдағы сияқты бот жұмыс істейтін құжаттар тізімі көрсетіледі, бірақ маңызды айырмашылық — осында құжаттарды тікелей қосу мүмкіндігі.
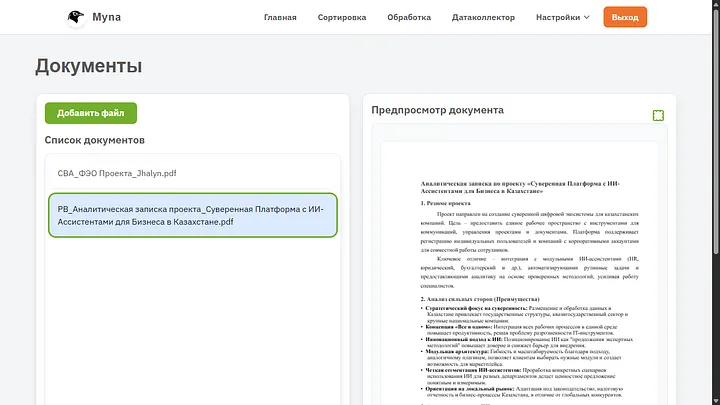
Бұл да алдын ала қарау терезесі. Егер біз файлды сұрыптаусыз және өңдеусіз қосқымыз келсе, мұны бір батырмамен жасауға болады. Бірақ ИИ оны тізілім кестесіне қосу және оған summary жасау үшін бәрібір оқиды.
Боттың жұмысын көрсету қалды. Менде Promptly жобасы бар, негізінен бұл жобадағы бот коды сол, тек қатты өзгертілген және әлдеқайда жеңілдетілген. Тесттік токен де содан қалды.
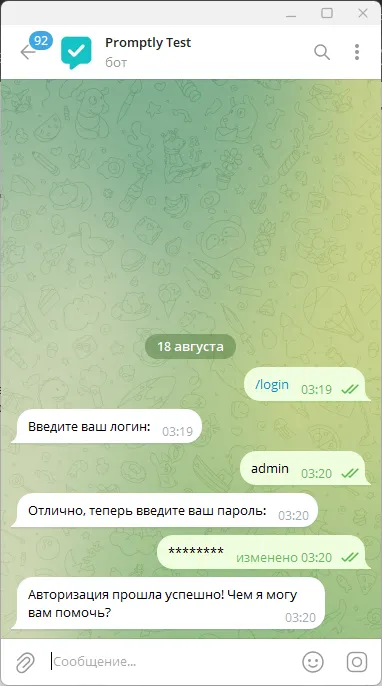
Авторизация дәл сол негізгі жобада қойылған есептік деректермен жүргізіледі. Бір есептік жазбаларды бірнеше пайдаланушы қолдана алады, мұнда қорқынышты ештеңе жоқ. Бірақ боттағы сессия тек 8 сағатқа созылады, содан кейін қайтадан авторизациядан өту қажет болады. Ақпарат бот үшін жеке кестеге жазылады және телеграм аккаунттың userID байланады, біз пайдаланушы туралы бұдан басқа ақпарат сақтамаймыз.
Міне, сұрау нәтижесі. Әр құжат үшін сұрау бойынша қысқаша сипаттама, содан кейін құжаттың өзіне сілтемесі бар инлайн батырма көрсетіледі.
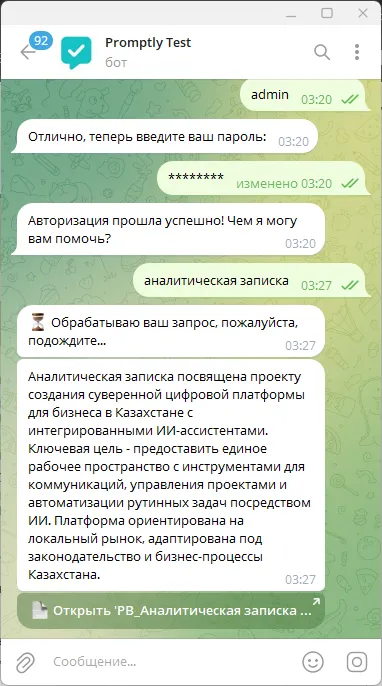
Егер сұрау бойынша релевантты құжаттар бірнешеу болса, онда хабарламалар да бірнешеу болады (бірақ үштен көп емес), олардың әрқайсысының қысқаша сипаттамасы мен құжаттарға сілтемелері болады. Боттың ішінде ішкі баптау бар, нәтижелерді қалай көрсетуді таңдауға болады — бір хабарламамен немесе жеке-жеке. Егер біз бір хабарлама болғанын қаласақ, жауап пайдаланушы құжаттардағы айырмашылықтарға немесе маңызды сәттерге назар аударатындай етіп генерацияланады, содан кейін баған түріндегі батырмалармен құжаттар тізімін алады.
Және әрине бонус — сұрауларды дауыспен де жіберуге болады, соның ішінде үш тілде (ағылшын, қазақ, орыс).
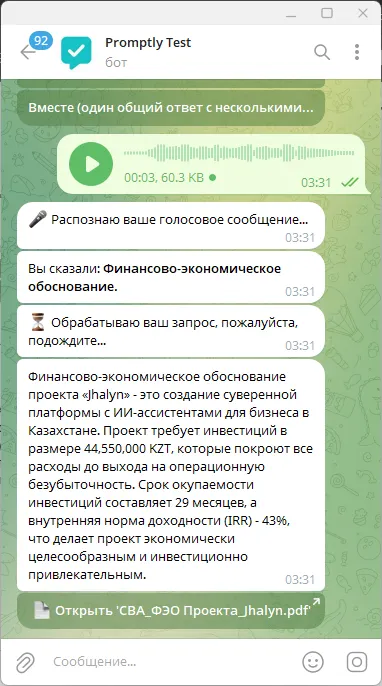
Осындай қызықты және функционалды жоба шықты.
Егер соңына дейін оқысаңыз, рақмет. Ешкім шаршамады деп үміттенемін, ал егер шаршасаңыз, міне, жобаның техникалық стегі туралы қосымша ақпарат:
Бүкіл жоба Python 3 тілінде жазылды, ал веб-қосымша үшін негіз ретінде Flask микро-фреймворкі алынды. Дерекқормен жұмыс істеу үшін SQLite қолданылады, бұл ретте асинхронды операциялар үшін aiosqlite, ал қарапайымдары үшін стандартты sqlite3 пайдаланылады. Файлдармен жұмыс файлдарды қауіпсіз жүктеуді қамтамасыз ететін стандартты Python (os, pathlib, shutil) модульдері мен Werkzeug көмегімен жүзеге асырылған. Құжаттарды өңдеу үшін жеке fileprocess модулі жасалды, ол өз кезегінде PDF файлдарынан мәтінді алу үшін extract_text_from_pdf пайдаланады. Excel файлдарын оқу меншікті read_xlsx_to_list модулі арқылы жүзеге асырылады, ал HTML мазмұнынан PDF генерациялау үшін Weasyprint қолданылады. Сыртқы ИИ API-мен жұмыс істеу үшін Google Gemini API-мен өзара әрекеттесуге арналған gemini меншікті орауыш модулі пайдаланылады. Жоба сонымен қатар логирование жүйесін, Markdown парсерін және JSON және тұрақты тіркестермен жұмыс істеуге арналған стандартты модульдерді қамтиды. Фронтендке келетін болсақ, ол Jinja2 шаблондарында құрылған және статикалық CSS және JS файлдарын пайдаланады. Сондай-ақ, пайдаланушы параметрлерімен, рөлдермен және суреттерді жүктеумен жұмыс қарастырылған, ал миграциялар мен дерекқорды инициализациялау «жүріс барысында» орын алады.
Шынымды айтсам, мен жай ғана ИИ-ден бұл абзацты VScode ішінде жазуын сұрадым :)
Оқығандарыңызға рақмет!